システムの開発に携わった経験のある方はもちろん、業務で利用するWebブラウザやメールやテキスト文章等でを「文字化け」の問題に遭遇した方は少なくないと思います。
想定していた内容の文字になっておらず、記号や普段目にしない難解な漢字等になってしまうやつですね。
発生すると焦るものです。
今回は文字化けが発生する仕組みを、学んでいきます。
文字コードの基本についてはこちらの記事を参照ください。
文字化けを起こしてみる
私のブログを文字化けさせてみます。
Webサイトの標準エンコード方式(文字符号化方式)は「UTF-8」です。WordPressでブログを作成している中で、普段は文字コードなんて特に意識しているところでは無いと思いますが、私のブログも「UTF-8」が使われています。
GoogleChromeブラウザでまずは普通に開きます。
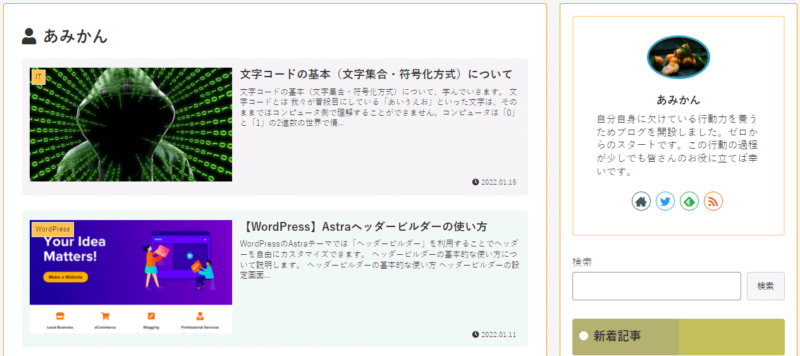
エンコード方式を「Shift_JIS」に変更しています。
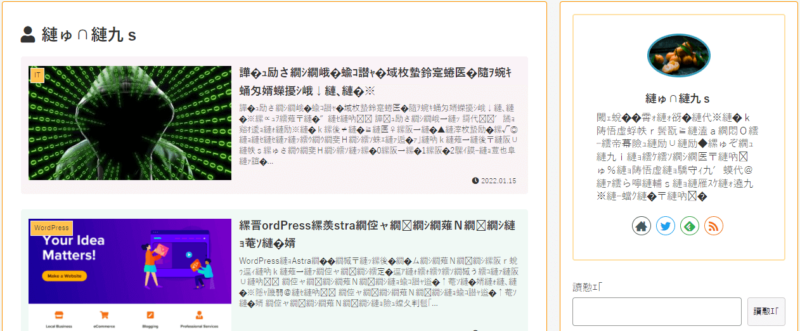
壊滅しました(笑)
文字化けの仕組み
「あみかん」という文字が「縺ゅ∩縺九s」という文字になってしまいました。
「あみかん」という文字を「UTF-8」でエンコードしてみると、3バイトで構成されていることが分かります。
UTF-8でエンコード
- あ→E38182
- み→E381BF
- か→E3818B
- ん→E38293
UFT-8が取り扱う文字集合は「Unicode」ですが、Unicodeには1byteから4byteの文字が収録されています。上記のひらがな4文字は3byteで「Unicode」という辞書に登録されているということですね。
それではこれを「Shift_JIS」でデコードしてみるとどうなるのでしょうか?
Shift_JISでデコード
- E381→縺
- 82E3→ゅ
- 81BF→∩
- E381→縺
- 8BE3→九
- 8293→s
一文字が2byteで構成されていることが分かります。UTF-8では12byteで4文字だったのが、Shift_JISでは12byteで6文字になっていますね。
「Shift_JIS」では1byteまたは2byteで文字が管理されています。この時点で「Uft-8」でエンコードされた3byte以上の文字を「Shift-JIS」で変換(デコード)したらマズイことが直感的に分かりますよね。また、「Shift_JIS」では取り扱う文字集合は「Unicode」はなく「JIS X 0208」等です。当然と言えば当然ですが、参照する辞書も違うということですね。
コンピュータは0と1の2進数の世界で情報を認識しますが、我々人間の目では分かりずらいし、横長になりすぎて煩わしいので、上記の「E38182」のように16進数で変換されて紹介されていることが多いと思います。
まとめ
UTF-8で作成された記事をShift_JISで表示し、文字化けすることが確認できました。
我々は人間が認識できる文字で普段はテキスト入力していますが、コンピュータの内部では、指定されたルールによる符号化(エンコード)/複合(デコード)に則って動いているということですね。
文字コードは複雑な世界でとっつき難い印象がありますが、少しずつ学んでいければと思います。
では良いブログライフを^^
あったかくして寝ろよ~